Tipos abstractos
Los tipos de datos abstractos son aquellos que:
- Se definen especificando constructores/operaciones.
- Pueden haber varias implementaciones para el mismo TAD.
- El problema muestra qué necesitamos representar y qué operaciones tener.
Para especificarlo debemos:
- Indicar su nombre
- Especificar constructores los cuales permiten crear elementos del tipo especificado.
- Especificar operaciones que permiten manipular elementos del tipo especificado.
- Especificar tipos de cada constructor/operación, explicar su función mediante lenguaje natural
- Definir precondiciones (restricciones)
- Especificar operaciones de destrucción que liberan memoria del tipo (en caso necesario)
Su implementación:
- Definir un nuevo tipo con el nombre de TAD especificado. Se utilizan tipos concretos/definidos.
- Implementar constructores respetando los tipos.
- Implementar operaciones respetando los tipos.
- Implementar operacion de destrucción si es que se ha reservado al contstruir los elementos.
- Pueden surgir nuevas restricciones que dependen de cómo implementamos el tipo.
- Pueden necesitarse operaciones auxiliares no especificadas en el tipo.
Listas
Colecciones de elementos de un mismo tipo, de tamaño variable. Todas son vacías o tienen un elemento al comienzo.
Especificación de listas
Para usar el tipo de las listas basta con especificarlas. No es necessario conocer la implementación para usar el TAD.
Sus constructores permiten crear listas vacías o agregar un elemento nuevo, respectivamente.
Las operaciones permiten manipular listas de acuerdo a la funcionalidad del TAD.
Ejemplo de uso:
Implementación de listas
La implementación del TAD lista utiliza punteros, dicha implementación es una lista enlazada.
Cada elemento de la lista estará alojado en un nodo conteniendo además un puntero hacia el siguiente.
Una lista será un puntero a un nodo (se sigue un patrón recursivo)
El constructor (lista vacía) se implementa fácilmente con el puntero
Lo que falta es la implementación del constructor (para agregar un elemento nuevo):
Para agregar un elemento a una lista , definimos un puntero y reservamos memoria al mismo.
El puntero apunta a un nodo (el cual contiene un elemento y un puntero).
El campo que apunta el puntero es el elemento que queremos agregar a
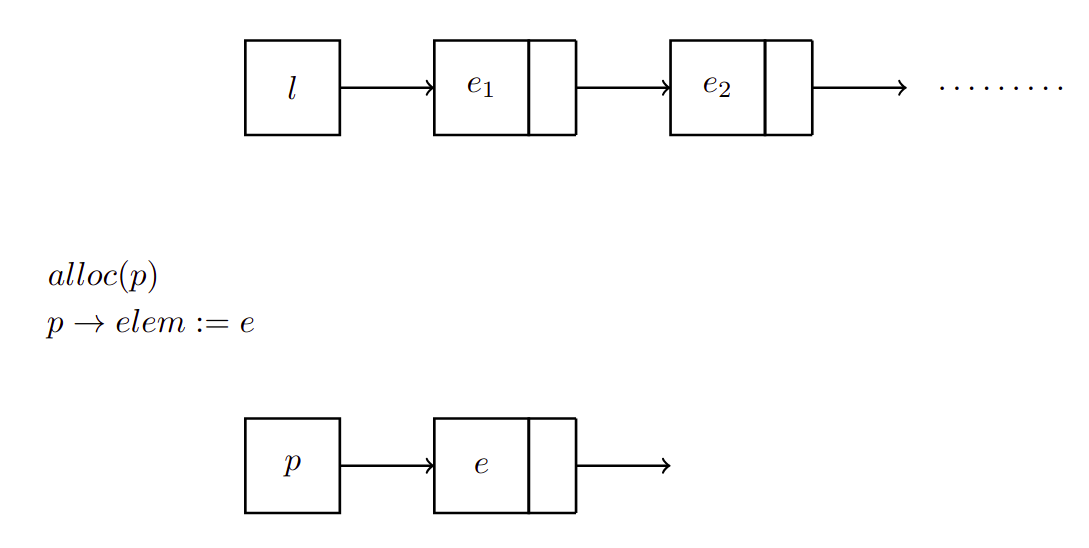
Ahora definimos el siguiente elemento de la lista, . El cual, es el que ya está apuntado por la lista
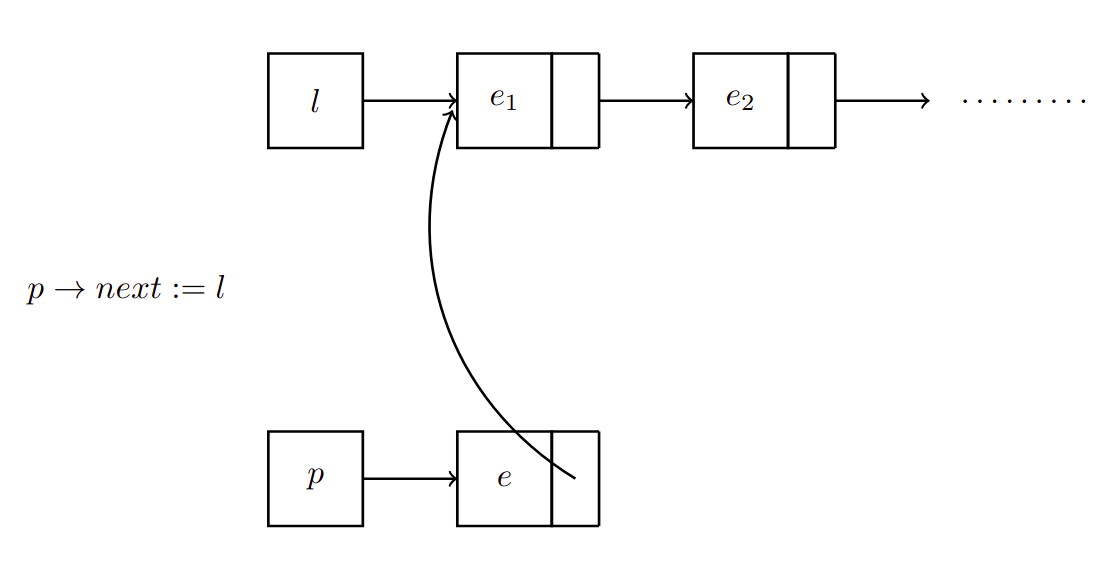
Entonces no debe apuntar a sino a (nuevo primer elemento)
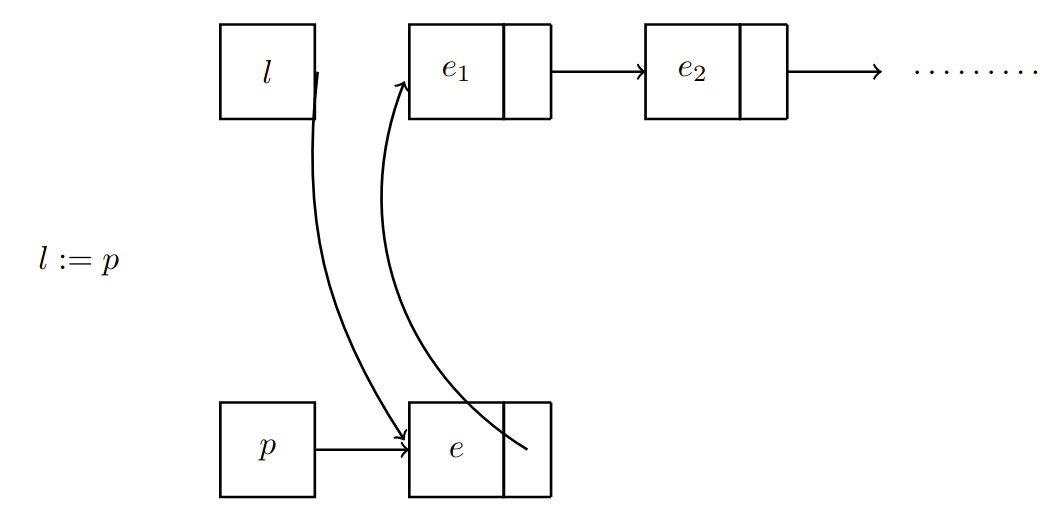
En el código tenemos:
Contador
El TAD contador se define por sus operaciones de inicializar un valor, incrementarlo, comprobar si su valor es el inicial y decrementarlo en caso de no serlo.
- La inicialización e incrementación son los constructores (generan todos los valores posibles del contador).
- La comprobación solo examina el contador,
- La decrementación no genera más valores que los obtenibles por inicializar/incrementar (no se decrementa si el valor es nulo)
Especificación de Contador
Implementación de Contador
La implementación de un contador es sencilla, se puede hacer con un natural.
Todas las operaciones son (constantes).
Pila
Una pila es una colección de datos de mismo tipo inicializada en vacía. Se pueden apilar y desapilar elementos, comprobar si hay primer elemento o examinarlo.
La pila sigue el principio LIFO (Last In, First Out)
Especificación de pila
Implementación de pila
Se puede utilizar un arreglo o una lista enlazada para implementar una pila, en este caso se usará un arreglo:
Cola
Una cola es una colección de datos de mismo tipo inicializada en vacía. Se puede encolar y decolar elementos, comprobar si es vacía, o examinar el primer elemento.
La cola sigue el principio FIFO (First In, First Out)
Especificación de cola
Implementación de cola
Se puede utilizar un arreglo o una lista enlazada para implementar una pila, en este caso se usará un arreglo:
Ejemplo de buffer de datos:
Sus funciones auxiliares:
- devuelve si el servicio productor-consumidor ha finalizado.
- comprueban si hay producción o demanda respectivamente.
- obtiene un producto desde el productor, y le envía al consumidor el producto .
Conjunto finito de elementos
Como su nombre lo indica, es un conjunto de elementos de un mismo tipo con una cantidad dinámica pero no infinita.
Como constructores tenemos:
- El conjunto vacío.
- Agregar un elemento a un conjunto.
Como operaciones tenemos:
- Chequear si un elemento pertenece al conjunto.
- Chequear si el conjunto es vacío.
- Unir un conjunto a otro.
- Intersecar un conjunto con otro.
- Obtener la diferencia entre dos conjuntos.
Especificación de conjunto finito de elementos
Árboles binarios
Consisten en nodos que almacenan un elemento y dos subestructuras, que pueden ser otro nodo o el vacío.\
- Uno de sus constructores es el árbol vacío,
- Su otro constructor es el nodo consistente de un elemento tipo y dos árboles.
En el nivel de un árbol hay a lo sumo nodos, (Por ejemplo, nivel nodos)
En un árbol “balanceado” la altura es del orden del donde es el número de nodos.
Podemos recorrer un árbol indicando caminos desde la raíz y representarlos como secuencias donde los elementos indican si bajamos por izquierda o derecha.
Su especificación es:
Implementación de árboles binarios
Su implementación es similar a la de listas enlazadas. Se define un tipo como tupla con un elemento y dos punteros a sí mismo:
Árboles binarios de búsqueda
Un arbol binario de búsqueda o ABB es aquel árbol donde:
1) Los valores alojados en el subárbol izquierdo de deben ser menores que el alojado en la raíz de .
2) Los valores alojados en el subárbol derecho de deben ser mayores que el alojado en la raíz de .
3) Las condiciones anteriores deben cumplirse para todos los subárboles de
Si el algoritmo está “balanceado”, es un algoritmo logarítmico.
Si queremos agregar un elemento se sigue este procedimiento:
1) Si es vacío, se forma el nodo que consta del elemento y los dos subárboles vacíos.
2) En caso contrario, se compara el elemento con la raíz del árbol .
- Si es menor que la raíz, se agrega al subárbol izquierdo.
- Si es mayor o igual a la raíz, se agrega al subárbol derecho.