Ordenación Avanzada
Ordenación por intercalación (Merge Sort)
Este algoritmo consiste en dividir el arreglo en dos mitades (hasta llegar a arreglos de un elemento), ordenar cada mitad y luego intercalarlas.
En pseudocódigo:
El arreglo dejará de dividirse cuando este tenga un solo elemento, en ese caso, ya estará ordenado.
El procedimiento se encarga de intercalar dos arreglos ordenados, en la siguiente imagen se puede ver su invariante, donde cada sublista está siempre ordenada antes de intercalarlas.
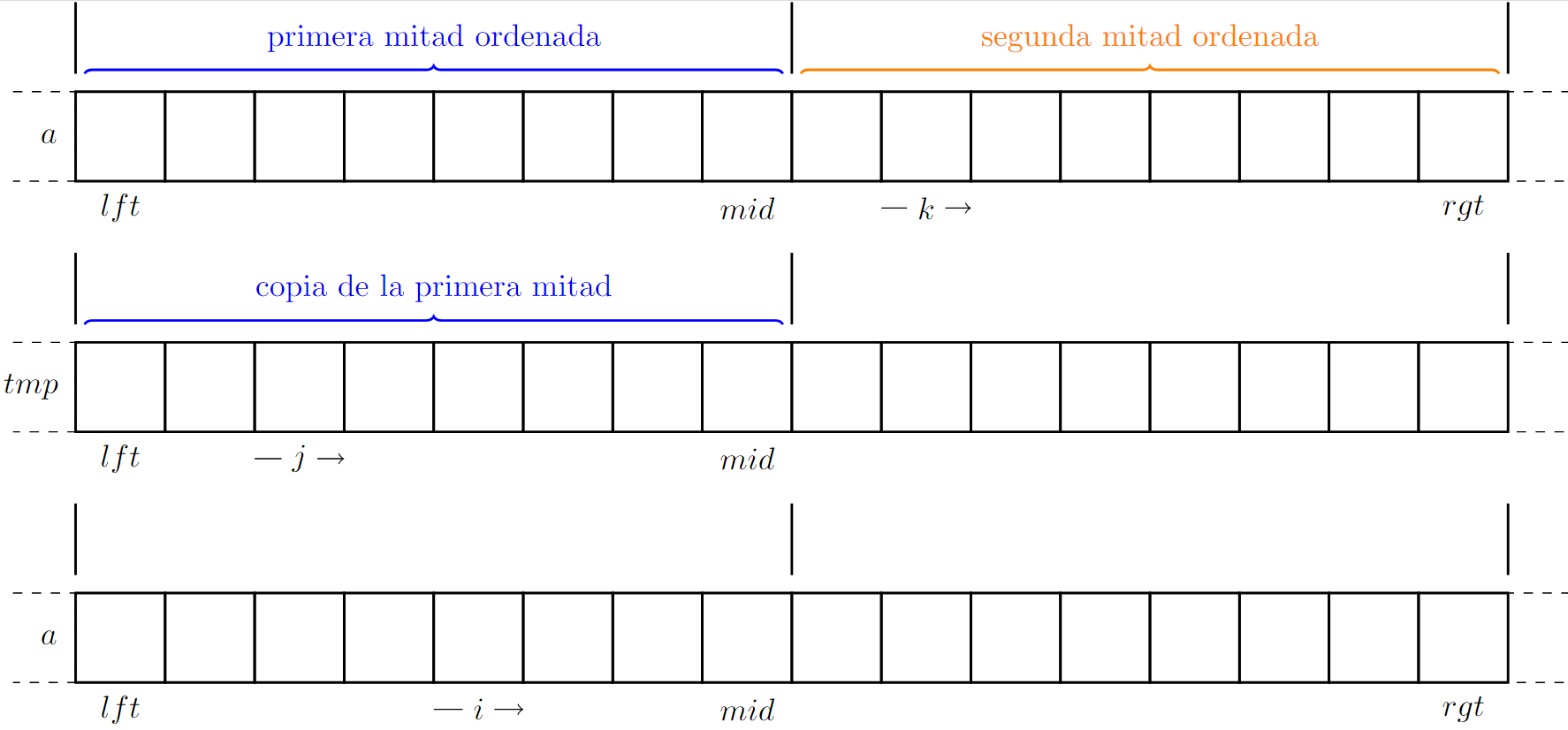
Su pseudocódigo es:
Se considera el caso en el que todos los elementos de la segunda mitad se comparan, lo cual sucede si , por lo que completamos con los elementos restantes de la primera mitad.
Este algoritmo posee una complejidad de en el peor caso.
Ordenación rápida (Quick Sort)
Se toma el primer elemento del arreglo como pivote, se colocan los elementos menores a la izquierda y los mayores a la derecha. Luego se repite el proceso con las dos mitades.
En pseudocódigo:
La invariante de puede verse en la siguiente imagen, donde y se cumple que todos los elementos a la izquierda son menores o iguales a y los de la derecha son mayores a .
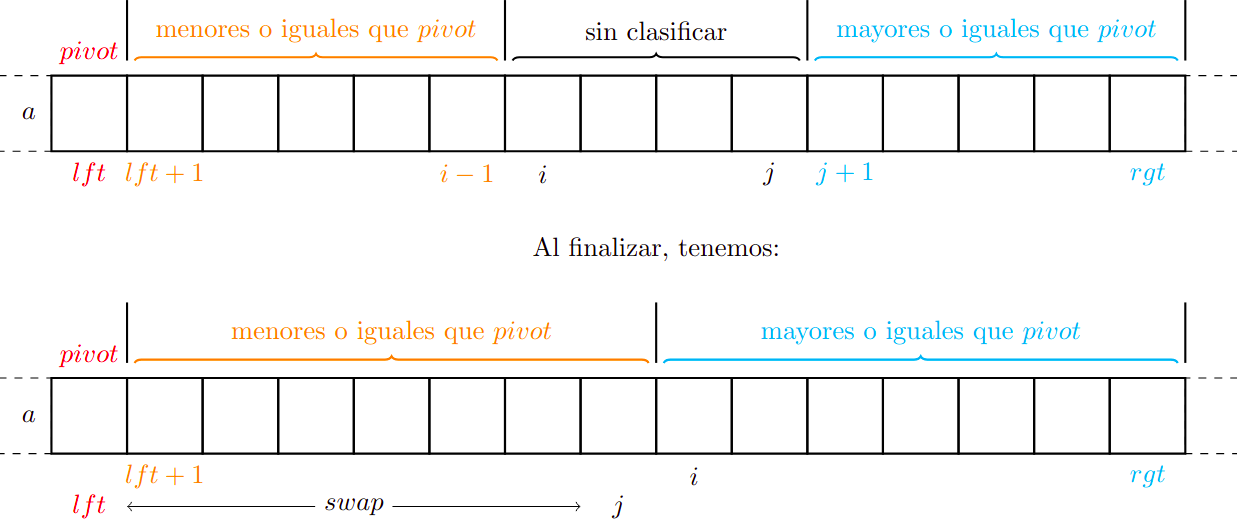
El pseudocódigo de es:
Comparamos si es menor o igual al pivote y si es mayor o igual. De ser el caso aumentamos los índices, de lo contrario intercambiamos los elementos. Por último, ubicamos correctamente a y asignamos su nuevo índice.
En el peor caso, la complejidad de este algoritmo en el peor caso es de , pero en promedio es de . Por lo general es más rápido que Merge Sort, es una buena opción para conjuntos de datos que caben en memoria. De lo contrario, Merge Sort es más eficiente.